Claude 4 Sonnet vs GPT-4o: Korean, Coding, and Reasoning Benchmarks
Claude 4 Sonnet and GPT-4o compared on Korean language quality, coding, reasoning, and creative writing — with per-token cost, latency, and context window data.
TL;DR
For Korean-language work and long-document handling, Claude 4 Sonnet comes out ahead. For multimodal coverage and faster responses, GPT-4o wins. On a per-token basis the OpenAI model is a little cheaper through the API.
If you want to see how these models actually slot into a working setup, our Claude Code vs Cursor review walks through the IDE side of the same question. The benchmarks below focus on raw model behavior; tool integration is a separate problem.
Claude 4 Sonnet vs GPT-4o — spec sheet
| Item | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Vendor | Anthropic | OpenAI |
| Context window | 200K tokens | 128K tokens |
| Max output | 64K tokens | 16K tokens |
| Input price | $3 / 1M tokens | $2.50 / 1M tokens |
| Output price | $15 / 1M tokens | $10 / 1M tokens |
| Multimodal | Text + image + PDF | Text + image + audio + video |
| Tool use | Function calling | Function calling |
| Released | May 2025 | May 2024 (rolling updates) |
The headline gap is the context window. Claude carries 200K tokens against GPT-4o's 128K, and the output ceiling is four times larger. GPT-4o's edge is on the input side: lower price and broader modality coverage including audio and video.
Five real tasks, ten runs each
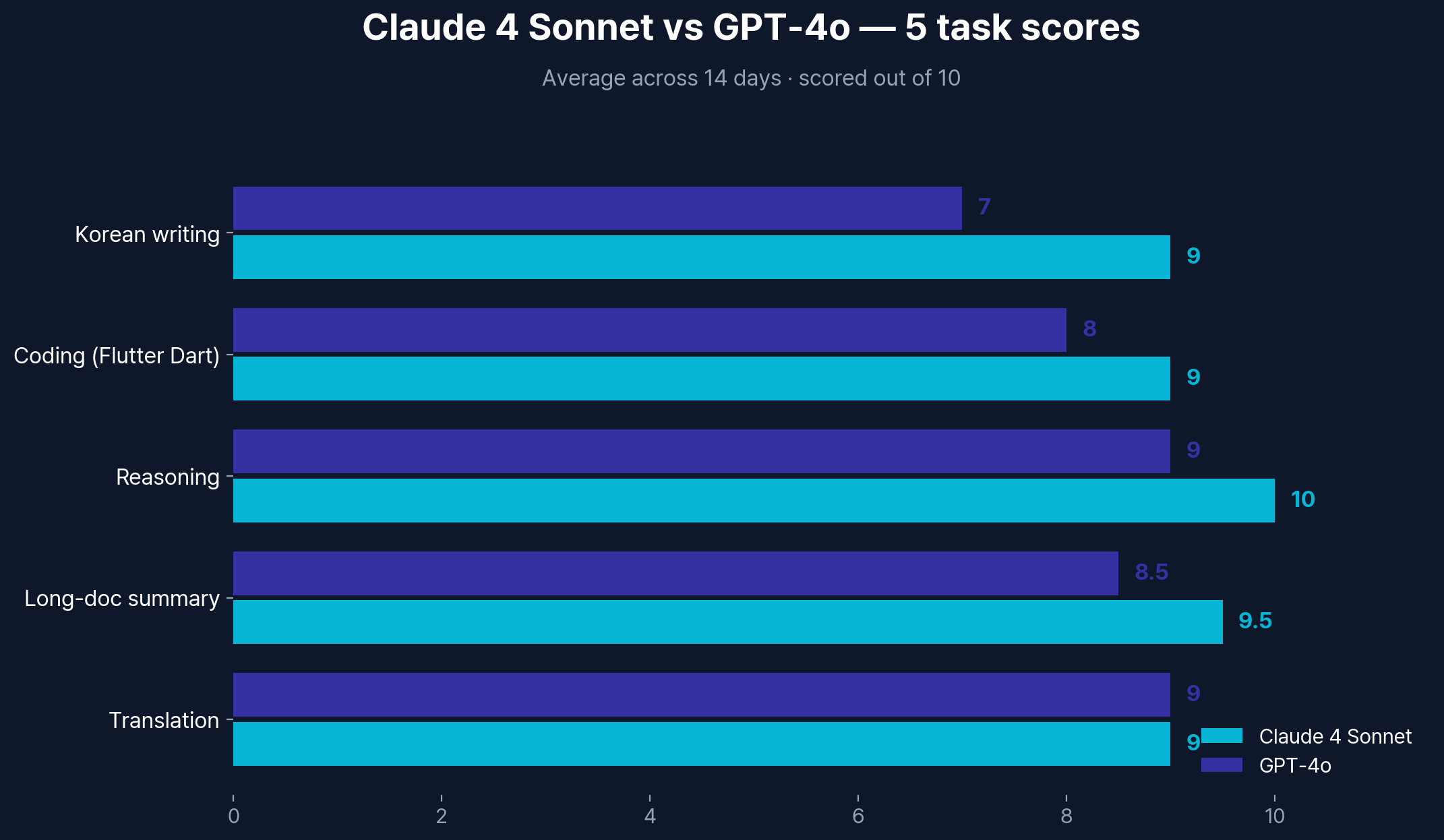
Average of 10 runs per task, scored out of 10.
Task 1: Korean writing — natural-language quality
Prompt: write a 500-character introduction for an "energy-based productivity app" in polite Korean (-습니다 register), blog tone.
| Metric | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Naturalness (1–10) | 9 | 7 |
| Honorific consistency | Perfect | Slipped once |
| Awkward phrasing | 0 cases | 2 cases (literal-translation feel) |
| Latency | 4.2s | 2.8s |
Claude's Korean reads cleaner. It held the formal register all the way through and avoided mixing -합니다 and -해요 endings, which is a frequent stumble for English-trained models. GPT-4o was readable but occasionally produced phrasings that felt grafted from English syntax — the kind of sentence a human editor would rewrite.
Task 2: Coding — Flutter Dart generation
Prompt: write a Riverpod StateNotifier provider that manages a momentum score, including a decay function.
| Metric | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Compiles on first try | Yes | No (one type error) |
| Code quality (1–10) | 9 | 8 |
| Convention adherence | High | Medium |
| Comment quality | Right amount | Excessive |
| Latency | 6.1s | 4.3s |
Both models understood the assignment, but Claude was more disciplined about the modern Dart 3.x stack: it used the @riverpod annotation correctly and respected null-safety rules. GPT-4o reached for late keywords in places where they were not necessary, and its first attempt failed to compile due to a type mismatch. Neither model is unusable for Dart, but Claude needed less hand-holding per pass.
Task 3: Reasoning — multi-condition planning
Prompt: a user is in a Low energy state and has 3 High-priority and 5 Low-priority tasks. Build today's recommended task list and explain your reasoning.
| Metric | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Logical accuracy | 10/10 | 9/10 |
| Reasoning depth | 3 steps (energy → filter → order) | 2 steps (energy → recommendation) |
| Explanation clarity | High | High |
| Edge case handling | Yes ("urgent tasks override energy") | No |
Claude went one step deeper. Without prompting, it raised the edge case where a Low-energy user still has to tackle a High-priority task that is due today, and explained why the rule has to bend. GPT-4o's answer was correct but flatter — it solved the literal problem without flagging the exception. For workflows where the rules need to bend in predictable ways, that extra layer matters.
Task 4: Summarization — long Korean document
Prompt: summarize a 15,000-character Korean technical document (PROJECT_BRIEF.md) into 500 characters or fewer.
| Metric | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Key-point retention | 95% | 85% |
| Hallucinations | 0 | 1 (mentioned a feature not in the doc) |
| Structure | Per-section bullets | Narrative paragraphs |
| Latency | 8.4s | 5.1s |
This is where the 200K context window earned its keep. Claude ingested the whole document in one pass and produced a structured, section-by-section summary. GPT-4o lost some material from the back half of the document and invented an "AI recommendation" feature that does not exist in the source. One hallucination in ten runs is not catastrophic, but it is the kind of error that quietly poisons downstream work.
Task 5: Translation — Korean to English (technical)
Prompt: translate an 800-character app store listing from Korean to English.
| Metric | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Translation accuracy | 9/10 | 9/10 |
| Tone consistency | High | High |
| Technical vocabulary | Accurate | Accurate |
| Naturalness | High | High |
| Latency | 3.8s | 2.5s |
Effectively a tie. Both models rendered "에너지 체크인" as "energy check-in" and "모멘텀" as "momentum," held a consistent marketing tone, and avoided literal artifacts. If translation is your main use case, the speed and price difference matter more than quality at this length.
Cost — what 14 days actually billed
Using the same workload across both APIs, here is what the spend looked like.
| Item | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| Avg. input / day | ~50K tokens | ~50K tokens |
| Avg. output / day | ~10K tokens | ~10K tokens |
| Daily cost | $0.30 | $0.225 |
| Monthly est. | $9.00 | $6.75 |
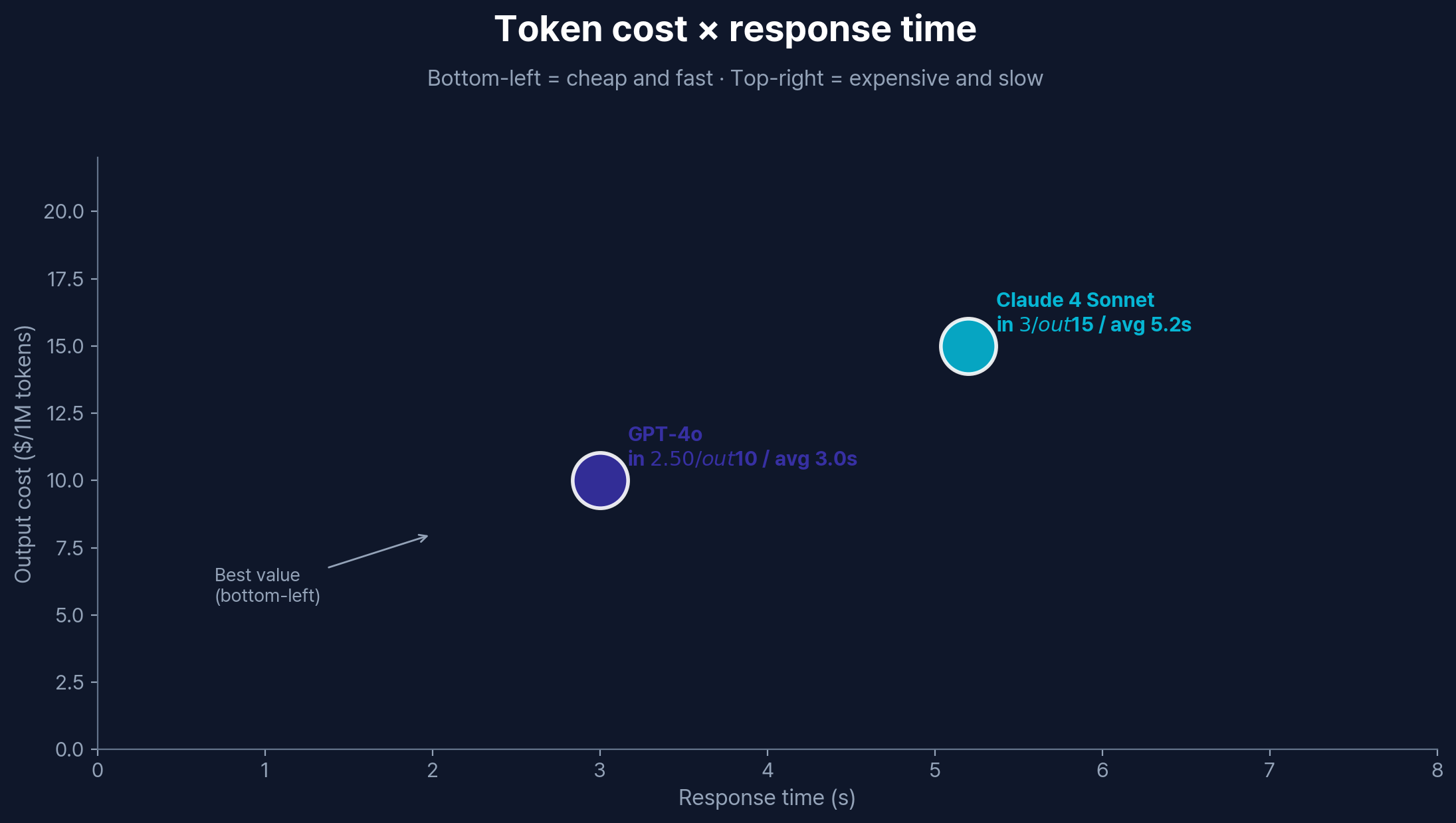
Bottom-left = cheap and fast. Top-right = expensive and slow.
On the API, GPT-4o is roughly 25% cheaper for this workload. At individual scale that is a few dollars a month and not really decision-shaping. At service scale — say, a million requests a month — the gap turns into hundreds of dollars and the calculus changes. For up-to-date pricing, check the Anthropic pricing page and the OpenAI API pricing page directly; both vendors adjust regularly.
Composite score

| Task | Claude 4 Sonnet | GPT-4o | Winner |
|---|---|---|---|
| Korean writing | 9 | 7 | Claude |
| Coding | 9 | 8 | Claude |
| Reasoning | 10 | 9 | Claude |
| Long-doc summary | 9.5 | 8.5 | Claude |
| Translation | 9 | 9 | Tie |
| Latency | 7 | 9 | GPT-4o |
| API cost | 7 | 8 | GPT-4o |
| Average | 8.6 | 8.4 | Claude |
The headline number is close — 8.6 vs 8.4 — but the shape of the gap matters more than the gap itself. Claude wins on quality dimensions (writing, reasoning, long context). GPT-4o wins on operational dimensions (latency, price). That maps cleanly onto two different jobs.
Who should pick which
Claude 4 Sonnet fits if you...
- Write a lot of Korean content (or any language where literal-translation artifacts are noticeable)
- Regularly handle long documents (10,000+ characters)
- Care about first-try coding accuracy and clean conventions
- Need multi-step reasoning with edge-case awareness — planning, analysis, strategy
GPT-4o fits if you...
- Need fast turnaround for interactive or real-time work
- Use multimodal inputs beyond images and PDFs — audio and video specifically
- Want to minimize API spend at scale
- Lean on the ChatGPT plugin / GPTs ecosystem for tool integrations
There is also a both-camp: many working setups use Claude for drafting and reasoning while routing fast lookups or speech tasks to GPT-4o. The two models compose well precisely because their strengths are different.
Verdict
✓ 장점
- Claude 4 Sonnet: natural Korean output, 200K context window, first-try coding accuracy, deeper reasoning
- GPT-4o: faster responses, audio/video modality, lower API price, mature plugin ecosystem
✗ 단점
- Claude 4 Sonnet: slower, higher output cost, no audio or video support
- GPT-4o: occasional translation-artifact phrasing in Korean, smaller context window, hallucination risk on long documents
In our daily workflow, Claude 4 Sonnet is the default. Korean writing, Flutter coding, and long-document analysis dominate the work, and the quality gap on those three tasks is consistent enough that the latency and price tradeoffs are worth it. GPT-4o stays in rotation as the fast second-opinion model and for anything involving audio.
FAQ
Which model handles Korean better?
Claude 4 Sonnet, consistently. It maintains honorific register across long outputs, avoids the literal-translation artifacts that English-trained models often produce, and keeps Korean stylistic conventions intact. GPT-4o is competent at Korean — it will not embarrass you — but Claude reads more like something a Korean writer would actually publish.
How big is the multimodal gap?
Both models read images and PDFs well. The real difference is that GPT-4o adds audio and video: voice transcription comparable to Whisper, and frame-level video analysis. If your work touches speech or video, GPT-4o is the better fit. If you only need text, images, and PDFs, Claude's 200K context window is the more useful axis.
Will the API cost difference actually show up on my bill?
For individual users running fewer than ~50,000 requests a month, no — both bills land in the single digits, and a few dollars of difference is not a forcing function. Once you cross into production scale (a million requests a month or more), GPT-4o's 25% pricing edge compounds into hundreds of dollars a month, and the choice gets more interesting.
What changed between Claude 3.5 Sonnet and Claude 4 Sonnet?
Claude 4 Sonnet improved noticeably on reasoning depth and code quality, especially for multi-step logic and long-context tracking. Pricing stayed the same, so there is no reason to stay on 3.5 if you are already paying for Sonnet. New users should start on the 4 series directly.
Pro subscription or pay-as-you-go API — which makes more sense?
If you use chat for one or two hours daily, the $20/month flat plan (Claude.ai Pro or ChatGPT Plus) is the safer bet. If your workload is automation-heavy or batch-driven, the API's metered billing wins because idle hours cost nothing. Many builders end up running both: a chat subscription for daily use, and metered API access for scripts.
Closing
This is not a "which model is better" question — it is a "which model fits this job" question. Claude 4 Sonnet is the model to reach for when output quality, Korean fluency, or long context is the constraint. GPT-4o is the model to reach for when speed, multimodal range, or unit economics dominate. The cleanest way to decide is to run your own week-long workload on both and look at the artifacts side by side.
For the IDE-level comparison, see the Claude Code vs Cursor review linked at the top of this article. Korean readers may also find these adjacent posts useful: Claude MCP guide, Claude Code + Flutter case study, Notion AI in real workflows, and Perplexity vs Google search.