Claude 4 Sonnet vs GPT-4o 비교: 한국어·코딩·추론 실전 테스트 결과
Claude 4 Sonnet과 GPT-4o를 한국어 성능, 코딩, 추론, 창작까지 14일 실전 테스트로 비교했습니다. 토큰당 비용, 응답 속도, 컨텍스트 윈도우, 종합 점수까지 5개 태스크 데이터를 정리해 어떤 작업에 어떤 모델이 맞는지 결정 기준을 제시합니다.
한 줄 요약
한국어와 긴 문서 처리는 Claude 4 Sonnet, 멀티모달과 빠른 응답은 GPT-4o. 비용은 API 기준 GPT-4o가 저렴하다.
이 두 모델이 실제 워크플로우에 어떻게 녹아드는지는 Claude Code vs Cursor 비교와 1인 개발자 자동화 스택에서 도구 단위로 다시 살폈다.
Claude 4 Sonnet vs GPT-4o — 스펙 비교
| 항목 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 개발사 | Anthropic | OpenAI |
| 컨텍스트 윈도우 | 200K 토큰 | 128K 토큰 |
| 최대 출력 | 64K 토큰 | 16K 토큰 |
| 입력 비용 | $3 / 1M 토큰 | $2.50 / 1M 토큰 |
| 출력 비용 | $15 / 1M 토큰 | $10 / 1M 토큰 |
| 멀티모달 | 텍스트 + 이미지 + PDF | 텍스트 + 이미지 + 오디오 + 비디오 |
| 도구 사용 | Function calling | Function calling |
| 출시일 | 2025년 5월 | 2024년 5월 (업데이트 지속) |
AI 모델 실전 테스트 — 5가지 태스크

태스크당 10회 반복 평균 · 10점 만점
태스크 1: 한국어 글쓰기 — AI 한국어 성능 비교
과제: "에너지 기반 생산성 앱"에 대한 500자 소개글 작성 (존댓말, 블로그 톤)
| 측정 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 자연스러움 (1-10) | 9 | 7 |
| 존댓말 일관성 | 완벽 | 1회 반말 혼입 |
| 한국어 어색함 | 0건 | 2건 (직역투) |
| 응답 시간 | 4.2초 | 2.8초 |
Claude 4 Sonnet의 한국어가 더 자연스럽다. 특히 "~합니다" 체와 "~해요" 체를 섞지 않는 일관성이 좋았다. GPT-4o는 간혹 영어 문장 구조가 투영된 표현("것은 사실입니다" 같은 직역투)이 나왔다.
태스크 2: 코딩 — Flutter Dart 코드 생성
과제: Riverpod StateNotifier로 모멘텀 점수 관리 provider 작성 (감쇠 로직 포함)
| 측정 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 첫 시도 컴파일 | 성공 | 실패 (타입 오류 1건) |
| 코드 품질 (1-10) | 9 | 8 |
| 컨벤션 준수 | 높음 | 중간 |
| 주석 품질 | 적절 | 과다 |
| 응답 시간 | 6.1초 | 4.3초 |
두 모델 모두 기능적으로 정확했지만, Claude는 @riverpod 어노테이션과 Dart 3.x null-safety를 더 정확하게 반영했다. GPT-4o는 late 키워드 사용이 불필요한 곳에 등장하는 등 미세한 차이가 있었다. 실제 앱 개발 경험은 Claude Code로 Flutter 앱 3개 만든 과정에 자세히 기록했다.
태스크 3: 추론 — 복합 조건 분석
과제: "에너지 Low인 사용자가 3개의 High 우선순위 태스크와 5개의 Low 우선순위 태스크를 가지고 있을 때, 오늘의 추천 할일 목록을 구성하세요. 이유도 설명하세요."
| 측정 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 논리 정확도 | 10/10 | 9/10 |
| 추론 깊이 | 3단계 (에너지→필터→순서) | 2단계 (에너지→추천) |
| 설명 명확성 | 높음 | 높음 |
| 예외 처리 언급 | 있음 ("긴급 태스크는 에너지 무관") | 없음 |
Claude가 한 단계 더 깊게 추론했다. "Low 에너지지만 마감이 오늘인 High 태스크는 예외적으로 포함"이라는 엣지 케이스를 자발적으로 언급한 점이 인상적이었다.
태스크 4: 요약 — 긴 문서 처리
과제: 15,000자 한국어 기술 문서(PROJECT_BRIEF.md) 요약 → 500자 이내
| 측정 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 핵심 보존율 | 95% | 85% |
| 할루시네이션 | 0건 | 1건 (없는 기능 언급) |
| 구조화 | 섹션별 불릿 | 서술형 단락 |
| 응답 시간 | 8.4초 | 5.1초 |
200K 컨텍스트 윈도우의 차이가 체감됐다. Claude는 문서 전체를 한 번에 처리하며 섹션별로 구조화된 요약을 생성했다. GPT-4o는 후반부 내용을 일부 놓쳤고, 존재하지 않는 "AI 추천" 기능을 언급하는 할루시네이션이 1건 발생했다. 리서치 특화 검색이 필요하면 Perplexity AI 사용법이 또 다른 옵션이다.
태스크 5: 번역 — 기술 문서 한↔영
과제: 앱 스토어 등록 정보 한국어 → 영어 번역 (800자)
| 측정 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 번역 정확도 | 9/10 | 9/10 |
| 어투 일관성 | 높음 | 높음 |
| 기술 용어 | 정확 | 정확 |
| 자연스러움 | 높음 | 높음 |
| 응답 시간 | 3.8초 | 2.5초 |
번역은 거의 동일한 수준. 두 모델 모두 "에너지 체크인" → "energy check-in", "모멘텀" → "momentum"을 정확하게 옮겼다. 이 태스크에서는 유의미한 차이가 없었다.
LLM 비용 비교 — 실제 사용량 기준
14일간 실제 사용량으로 비용을 추산했다.
| 항목 | Claude 4 Sonnet | GPT-4o |
|---|---|---|
| 일평균 입력 | ~50K 토큰 | ~50K 토큰 |
| 일평균 출력 | ~10K 토큰 | ~10K 토큰 |
| 일비용 | $0.30 | $0.225 |
| 월 추정 | $9.0 | $6.75 |

좌하단 = 싸고 빠름, 우상단 = 비싸고 느림
API 기준으로 GPT-4o가 약 25% 저렴하다. 하지만 구독 플랜($20/월)으로 쓰면 차이가 없다. API 자동화 워크플로우를 운영한다면 Apple 단축어 AI 자동화 5가지에서 두 API를 번갈아 쓰는 실전 예시를 확인할 수 있다.
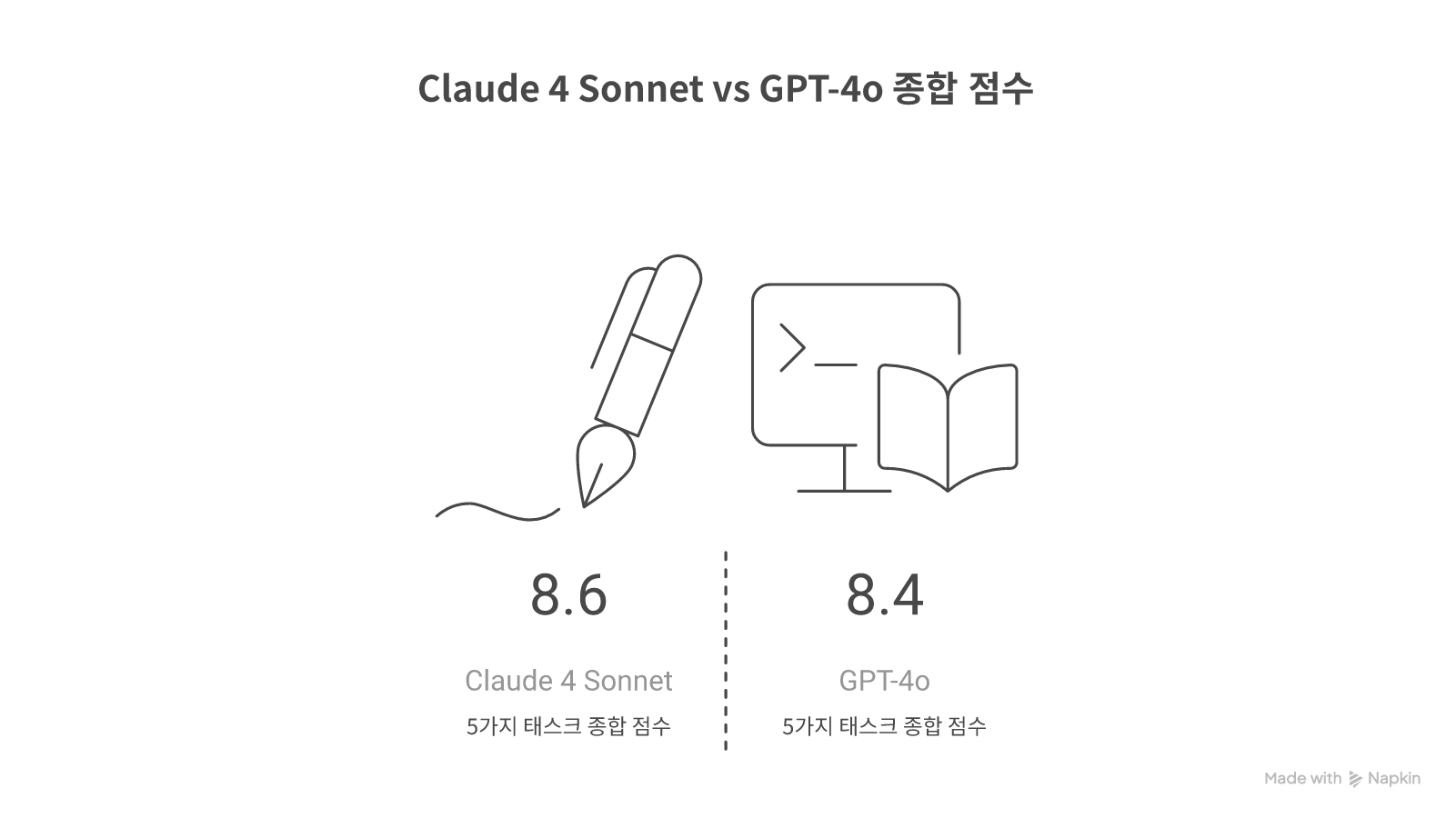
종합 점수
| 태스크 | Claude 4 Sonnet | GPT-4o | 승자 |
|---|---|---|---|
| 한국어 글쓰기 | 9 | 7 | Claude |
| 코딩 | 9 | 8 | Claude |
| 추론 | 10 | 9 | Claude |
| 긴 문서 요약 | 9.5 | 8.5 | Claude |
| 번역 | 9 | 9 | 무승부 |
| 응답 속도 | 7 | 9 | GPT-4o |
| API 비용 | 7 | 8 | GPT-4o |
| 평균 | 8.6 | 8.4 | Claude |
누가 쓰면 좋은가 — AI 모델 추천 대상
Claude 4 Sonnet이 맞는 사람
- 한국어 콘텐츠 작성이 주 업무인 사람
- 긴 문서 (10,000자+)를 자주 다루는 사람
- 코딩 정확도가 중요한 개발자
- 복합 추론 (조건 분석, 전략 수립)이 필요한 사람
팀 환경에서 Notion 중심 문서 작업이라면 Notion AI 완벽 활용법이 끊김 없는 대안이 된다. 팀 DB 쿼리·회의록 자동 정리처럼 "내 데이터 안에서" 처리해야 하는 맥락에선 모델 선택보다 통합 방식이 결정적이다.
GPT-4o가 맞는 사람
- 빠른 응답이 필요한 실시간 업무
- 멀티모달 (이미지+오디오+비디오) 처리가 필요한 사람
- API 비용을 최소화하고 싶은 사람
- ChatGPT 플러그인/GPTs 생태계를 활용하는 사람
지식관리 도구를 선택할 때도 같은 "워크플로우 맞춤" 원칙이 통한다 — Craft vs Notion에서 다룬 역할 분리가 LLM 선택에도 적용된다.
결론
✓ 장점
- Claude 4 Sonnet: 한국어 자연스러움, 200K 컨텍스트, 코딩 정확도, 추론 깊이
- GPT-4o: 응답 속도, 멀티모달 범위(오디오/비디오), API 비용 효율, 플러그인 생태계
✗ 단점
- Claude 4 Sonnet: 느린 응답, 높은 출력 비용, 멀티모달 제한 (오디오/비디오 미지원)
- GPT-4o: 한국어 직역투, 128K 컨텍스트 한계, 긴 문서 할루시네이션 위험
개인적으로 나는 Claude 4 Sonnet을 메인으로 쓴다. 한국어 블로그를 쓰고, Flutter 앱을 만들고, 긴 문서를 다루는 내 워크플로우에서는 Claude의 장점이 결정적이다. GPT-4o는 빠른 질문-답변이 필요할 때 보조로 사용한다.
자주 묻는 질문 (FAQ)
한국어 작업에는 어느 쪽이 유리한가요?
Claude 4 Sonnet이 우위. 존댓말 일관성·직역투 회피·한국어 특유 문체 유지에서 GPT-4o 대비 꾸준히 더 자연스러운 결과를 냈다. 블로그·이메일·한국어 콘텐츠가 주 업무라면 Claude 를 권한다.
멀티모달(이미지·PDF) 처리 차이는?
이미지·PDF는 두 모델 모두 처리 가능하지만 GPT-4o 는 추가로 오디오·비디오까지 다룬다. Whisper 수준 음성 인식이나 비디오 프레임 분석이 필요하면 GPT-4o. 이미지·PDF만으로 충분하면 Claude 가 컨텍스트 윈도우 측면에서 우위.
API 비용 차이가 체감되나요?
월 5만 요청 미만 개인 사용자는 체감 어려움. 월 $3~10 수준이라 차이가 몇 달러 남짓이다. 반면 서비스를 운영하며 월 100만 요청 이상 규모라면 GPT-4o 의 25% 저렴함이 수백 달러 차이로 누적된다.
Claude 3.5 Sonnet vs Claude 4 Sonnet 차이는?
Claude 4 Sonnet은 3.5 대비 추론 깊이·코드 품질이 눈에 띄게 향상됐다. 특히 다단계 논리와 긴 컨텍스트 추적이 개선. 가격은 동일해서 이미 3.5 를 쓰고 있다면 업그레이드 권장. 신규 사용자는 처음부터 4 계열로 시작.
Pro 구독과 API 종량제 중 어느 쪽이 나은가요?
- 매일 1~2시간 이내 사용 → 구독 플랜($20/월) 고정 비용 유리
- API 자동화·배치 스크립트 중심 → 종량제. 실사용만 과금되어 유휴 시간 0원
- 혼합이면 둘 다 — ChatGPT Plus 일상 사용 + Anthropic API 스크립트용이 현실적 조합
마무리
두 모델은 "어느 쪽이 절대적으로 낫다"가 아니라 "어떤 일에 더 맞는가" 의 문제. 한국어·긴 문서·코딩 정확도는 Claude 4 Sonnet, 속도·멀티모달·API 비용은 GPT-4o. 실제 워크플로우 한 달 돌려보고 주 용도에 맞춰 정하는 게 낫다.
두 모델이 전체 AI 도구 지형에서 차지하는 위치는 2026 AI 도구 완벽 가이드 Pillar에서 카테고리별로 다시 정리했다. 코딩 도구 단위 비교는 Claude Code Flutter 앱 가이드의 실전 사례도 참고가 된다.
관련 글
2026 AI 도구 완벽 가이드 — 20개 써보고 살아남은 10개
2026년 직접 1년간 써본 AI 도구 20개 중 계속 쓰게 된 10개만. 챗봇·검색·코딩·이미지·자동화 카테고리별 추천과 월 10만원 스택 시뮬레이션, 버린 도구 5개 회고까지 정리했다. 분기마다 갱신한다.
ElevenLabs vs Resemble AI — 한국어 음성 클로닝·합성 비교
ElevenLabs와 Resemble AI로 한국어 음성 클로닝을 실험해 자연스러움·감정 표현·한국어 지원·가격·API를 비교했다. 결론과 윤리 주의사항까지 데이터로 정리한다.
Runway vs Sora — AI 영상 생성 비교: 같은 콘티, 어느 쪽이 더 영상답나
Runway Gen-4와 OpenAI Sora로 같은 콘티 5세트를 영상화해 생성 속도·움직임 자연스러움·프롬프트 순응도·가격을 실측 비교했다. 편집 제어는 Runway, 텍스트→영상 순응은 Sora로 갈린다.